
Con la finalidad de dar un poco de continuidad a la temática del post anterior, ahora voy a mostrar las experiencia de probar el plugin "DataPlotly", el cual me pareció interesante, sobre todo por su versatilidad para la generación de gráficos.
Fuente de Datos
Para demostrar las ventajas del plugin vamos a emplear los mismos datos del post anterior, pero con la diferencia que ahora se está incluyendo un campo adicional que representa los valores de altitud de los centros poblados considerados; dichos datos han sido obtenidos empleando la herramienta de análisis "Point samplig Tool", partiendo de una capa raster de altitud, el procedimiento puede ser repasado aquí.

Figura 1: Se añadió una columna con datos de altitud de centros poblados
Características del DataPlotly
Es importante mencionar que el plugin "DataPlotly" permite la creación de gráficos al estilo D3 (Data-Driven Documents) y gracias a la librería de gráficos basados en JavaScript disponible de Plotly junto con el API de Python, podemos elaborar un grupo variado de ellos.
Dichos gráficos tienen la característica que son dinámicos e interactivos, es decir se tiene la facilidad de poder hacer por ejemplo acercamientos, asimismo poder brindarnos mayor información al pasar sobre ellos con el mouse, en fin debemos resaltar la facilidad que se tiene para su edición antes de obtener nuestro producto final.
Instalación
El DataPlotly solamente está disponible en la actualidad para la versión de desarrollo del QGIS, por lo tanto, podemos probarlo antes que salga la nueva versión 3.0 del QGIS. La instalación del mismo es sencilla desde nuestro administrador de complementos. Una vez instalado en plugin, lo veremos ubicado en la barra de herramientas listo para trabajar con nuestros datos.

Figura 2: Vista del plugin Data Plotly para su instalación
Conociendo a Data Plotly
Cuando activamos el plugin, nos aparece una ventana, la cual tiene dos elementos permanentes, el primero en la parte superior, relacionada a la selección del tipo de gráfico a elaborar (Plot Type) y el segundo en la parte inferior, que nos brinda la opción de generar más de un gráfico en una vista (SubPlots), el cual pueden representarse en filas o columnas (Figura 3).
Luego podemos apreciar que la ventana se subdivide en 5 pestañas; el primero denominado "Plot Properties", en donde se define la capa de datos a emplear e indicar las variables a usar, es decir los campos de datos que se van a representar (varía dependiendo del tipo de gráfico), del mismo modo, nos permite definir el tipo de marcadores a usar (puntos, líneas o puntos y líneas), luego las características de dichos marcadores, la coloración y la posibilidad de considerar el uso de transparencias.

Figura 3: Ventana de Data Plotly con opciones para configurar nuestro gráfico
En la segunda pestaña denominada "Plot Customizations", podemos terminar de configurar nuestro gráfico, agregando la leyenda, ingresando títulos al gráfico, etiquetar los ejes del gráfico, asimismo, podemos indicarle la información adicional que deseamos visualizar, el cual será mostrado al pasar el mouse por los marcadores de nuestro gráfico (Figura 4).
Luego de realizar la configuración de nuestro gráfico, ya se estaría listo para adicionar el mismo a un repositorio o contenedor de gráficos, haciendo clic al botón "Add Plot to Basket".

Figura 4: Vista de la pestaña para editar nuestro gráfico
Precisamente, nuestra siguiente pestaña denominada "Plot Basket" nos permite administrar nuestros gráficos, sobre todo si deseamos mostrar más de uno a la vez. Hay que tener en cuenta que al hacer cualquier modificación en las dos primeras pestañas, para que podamos verlos deberán ser adicionadas a este contenedor de gráficos, desde ahí ya podemos ir eliminando gráficos pasados, para ello solo seleccionamos de la tabla y luego hacemos clic en el botón "Remove Single Plot From List".
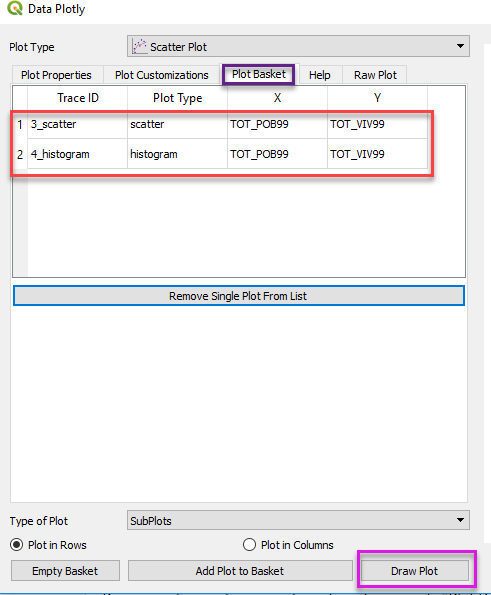
Figura 5: Vista del contenedor de gráficos generados
Finalmente ya teniendo claro lo que queremos mostrar en nuestra gráfica, podemos dar clic en el botón "Draw Plot", tal como se aprecia en la Figura 5.
Luego podemos ver que la siguiente pestañas denominada "Help", nos muestra la ayuda necesaria en función al tipo de gráfico elegido, el cual nos permite guiarnos para saber todas las opciones disponibles. Por última la pestaña "Raw Plot", muestra lo que sería el código fuente generado de nuestro gráfico, el mismo está en formato de texto HTML, el cual lo podemos copiar y guardarlo con dicha extensión y luego verlo en nuestro navegador web.

Figura 6: Vista de la ayuda del plugin y el código html generado
Gráficos Dinámicos
En esta parte vamos a mostrar algunos ejemplos de los gráficos que se pueden elaborar con este plugin, para ello empezaremos por el tipo "Scatter Plot". En sí, tomaremos este tipo de gráfico como modelo, con la finalidad de mostrar el dinamismo y lo interactivo que se puede lograr con el gráfico elaborado.

Figura 7: Editando nuestro gráfico incluyendo títulos y etiquetado a los ejes

Figura 8: Opción de editar los textos a mostrarse al pasar el mouse y un "RangeSlider"
el cual nos permite seleccionar un rango de datos que se puede mostrar.

Figura 9: Opciones para mostrar los valores al seleccionarlo apoyados con líneas de puntos

Figura 10: Se puede aplicar selección en caja o tipo lazo, resaltando un grupo de datos

Figura 11: Se puede mover y aplicar un acercamiento (zoom) a una zona de interés
Otros Tipos de Gráficos Posibles
Si bien no voy a entrar a interpretar los gráficos, si quisiera mostrarles que en función a nuestros datos, ha sido posible elaborar otro grupo de gráficos, los que se presentan en las siguientes figuras.

Figura 12: Gráfico o Diagrama de Caja (Basado en cuartiles y mostrando la media)

Figura 13: Vista de un histograma simple

Figura 14: Gráfico de pastel, agrupando los datos de población por categorías

Figura 15: Vista de un Gráfico Histograma 2D
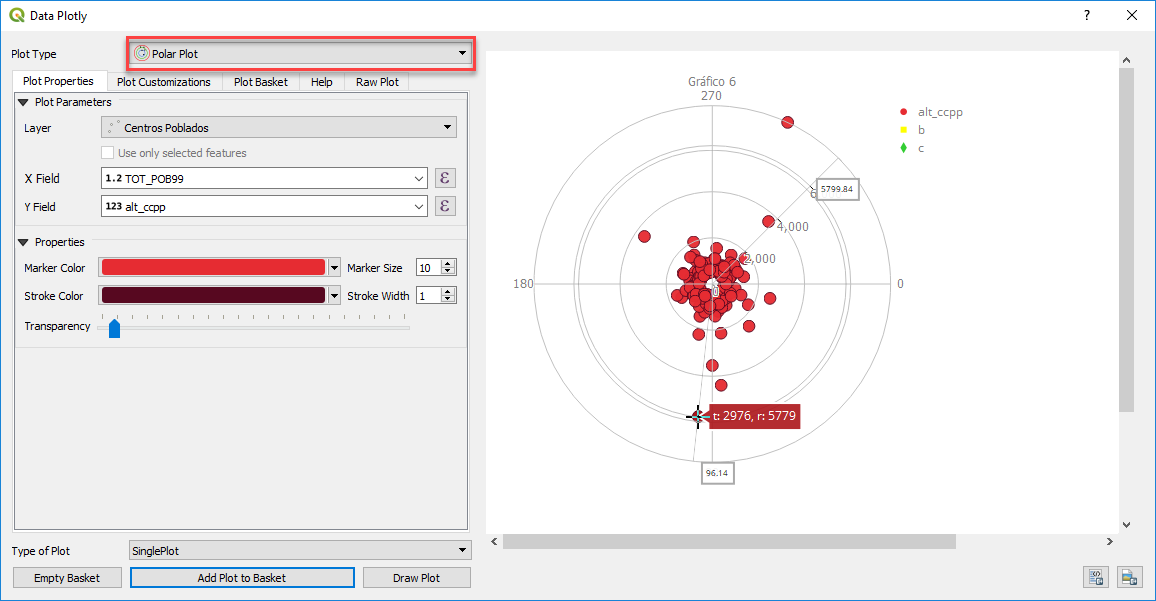
Figura 16: Vista de un Gráfico Polar

Figura 17: Vista de un Gráfico o Diagrama Ternario (empleo de tres variables)

Figura 18: Vista de un Gráfico en Contornos
Combinando Gráficos
Tal como lo indicamos previamente, podemos componer mas de un tipo de gráfico a la vez, para ello debemos ir generando y editando nuestros tipos de gráficos, luego adicionarlos a nuestra bandeja (basket), no olvidar seleccionar la opción de generar "SubPlots". Es importante tener en cuenta que no todos los tipos de gráficos soportan esta opción.

Figura 19: Combinando tres tipos de gráficos
Insertando Gráficos a Nuestro Mapa
Como paso final vamos a insertarlo en nuestro mapa con el que venimos trabajando, para ello previamente, tal como se muestra en la Figura 19, en la parte inferior de los gráficos existe la opción de exportarlo tanto como imagen como en formato html. Dentro de nuestro diseñador de impresión de los mapas, simplemente para nuestro caso, adicionamos como una imagen para el gráfico de pastel y como marco HTML a la imagen con los tres gráficos combinados.

Figura 20: Gráficos añadidos a nuestro mapa
Muy bien, ahora nuestro mapa podrá mostrar mayor información con los gráficos añadidos.




















