En esta oportunidad se presenta una herramienta disponible para las últimas versiones de QGIS, nos referimos al plugin "Visualist". Muchas veces contamos con datos que requerimos analizar y junto con ello la necesidad de mostrarlos o presentarlos de distintas maneras, en este caso, la herramienta se orienta no solo a mostrar datos, sino que a partir de ellos, podemos analizar la relación espacial existente. En general, esta herramienta de análisis nos permite generar mapas rápidos a partir de datos que representan ocurrencias o eventos (vectores de puntos y líneas).
Conociendo a Visualist
La ventaja del plugin es que, una vez instalado, se aloja en nuestra "Caja de herramientas de procesos", desde donde podemos ver las opciones disponibles. Intentaremos mostrar ejemplos con la mayoría de ellos.

Generación de mapas - Datos de ejemplo
Como primer paso vamos a seleccionar nuestros datos, para ello comparto un grupo de datos que pueden descargarlo desde aquí, los cuales contienen como puntos a un grupo de 155 centros poblados del Departamento de Apurímac en Perú, además de sus límites políticos (polígonos). Cuando desplegamos dichos datos tendremos una imagen similar al siguiente.

Chloropleth Map
Probaremos la primera opción, es decir la creación de un Chloropleth Map, a través del cual se logra representar una cantidad (número de eventos o porcentajes) por colores en función a las áreas administrativas que se indican.

El resultado por defecto sale en tonalidades de gris, pero con apoyo de las herramientas de simbología del QGIS podemos mejorar la presentación. Para este caso se usó una rampa de colores "Spectral" y el modo de clasificación Cuantil.


Como se pudo apreciar, es una manera de comparar los valores por regiones, pero además si nos vamos a los parámetros avanzadas, la información demográfica se pueda utilizar para ponderar las mediciones.

Si apreciaron los datos compartidos, podrán ver que no existe esa columna de datos llamada "SUM_TOT_POB". Para ello se hizo un ajuste de datos, es decir que nos apoyamos de otra herramienta, el cual se puede conseguirlo si lo buscamos como "Points statistics for polygons", con ella podemos generar un campo a partir de los datos de población existentes en los centros poblados, esto nos permitirá luego generar otro mapa en donde consideremos ese campo para realizar la distinción de colores. Si comparamos con el anterior mapa, existen dos provincias con el mismo número de puntos, por lo tanto tienen el mismo color, pero en este mapa, se distinguen los colores considerando la población existente.

Grid Map
En esta oportunidad se crea un mapa vectorial compuesto por cuadrículas de una misma dimensión, para ello nosotros definimos el tamaño de cada cuadrícula (metros). Es importante también definir la extensión, para ello se recomienda elegir la extensión de una capa de polígonos.
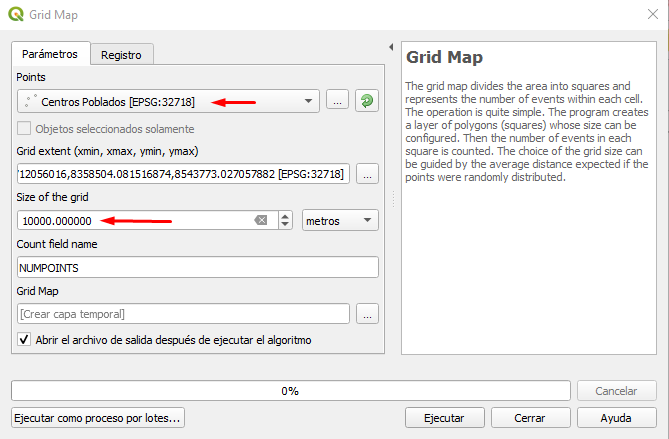
El resultado nos muestra los eventos enumerados en cada cuadrícula, diferenciados por colores graduados. Les recomiendo a que prueben distintos tamaños para ver los resultados que se obtienen, porque nosotros debemos tener claro cual sería el área que se piensa analizar en función a los eventos presentes, a mayor dimensión veremos que agrupará a una mayor cantidad de eventos (puntos) y la concentración podría ubicarse en otro lugar.

Según el manual del plugin, la elección del tamaño de la cuadrícula, puede guiarse por la distancia promedio esperada si los puntos se distribuyen al azar.
d = 0.5 * raíz cuadrada A/n
Donde A = área y n = número de eventos
Nearest Neighbours Clusters Map
El resultado de este mapa son polígonos que agrupan los puntos o eventos identificados de acuerdo a un análisis de vecinos más cercanos. El algoritmo trabaja sobre cada evento, utilizando un cuadrado centrado en la posición del evento y con un tamaño del doble de la distancia de búsqueda para seleccionar vecinos cercanos. Las distancias con estos vecinos se calculan y los eventos se consideran vecinos cercanos del evento si la distancia es menor o igual que la distancia de búsqueda.
Se selecciona el evento con más vecinos. Forman el primer hot spot (punto caliente). Se eliminan de la distribución y se selecciona el siguiente evento con el mayor número de vecinos. Forman el segundo hot spot, etc. El algoritmo es recursivo hasta que no haya más eventos con un número de vecinos mayor o igual al tamaño de cluster definido.

En nuestro caso estamos definiendo una distancia de 15 kilómetros, además de 5 eventos como el tamaño mínimo de clusters. Esto significa que el algoritmo agrupará como mínimo a 5 eventos que cumplan la condición de la distancia ( 15 km) existente entre ellos. Se diferencian por colores y tamaños de los polígonos de agrupamiento generados.

Si lo superponemos con un Grid Map, podemos apreciar que en un Clusters Map, las áreas se definen directamente por la distribución de los eventos, mientras que en un Grid Map, la agregación se define por el tamaño de la cuadrícula y la posición del área total.

Les recomiendo generar un mapa de calor (heatmap), con las herramientas del QGIS y superponerlo, verán que también podemos sacar algunas conclusiones.
Spatial Autocorrelation Map
La generación de este tipo de mapa es muy interesante, porque nos permite trabajar con los llamados indicadores de asociación espacial (LISA - Local Indicators of Spatial Association), lo cual según (2), son estadísticos que evalúan la existencia de grupos en la distribución espacial para una variable dada. Por ejemplo, si estamos estudiando la prevalencia de cáncer en una población determinada y se encuentra que en ciertas zonas al interior se tienen tasas más altas o más bajas que las esperadas; es decir, los valores que se producen están por encima o por debajo de los de una distribución aleatoria en el espacio.
En resumen el plugin permite realizar un análisis de las estadísticas de autocorrelación espacial local. Para ello implementa los siguientes indicadores:
- Local Moran's I: Análisis de agrupamientos (clusters) y valores atípicos (HH, HL, LH, LL) basado en covarianza.
- Getis-Ord Gi*: Análisis de puntos calientes (Hot-Spot) basados en el producto de intensidades.
Para entender el funcionamiento de éstos indicadores y sobre la autocorrelación espacial local, recomiendo revisar las referencias 3 y 4 y 5.
Cuando ejecutamos el plugin, lo haremos para cada indicador disponible, empleando los mismos datos de entrada. Se debe establecer también la matriz de pesos o ponderaciones espaciales (Spatial weight matrix), cuyos valores son una función de cierta medida de contigüidad en los datos originales. En la referencia 5, se aprecia una gráfica que diferencian las opciones del plugin (Queen - Reina, Rook-Torre y Bishop-Alfil), los cuales toman dichos nombres en referencia a los movimientos que realizan sobre un tablero de ajedrez.

El resultado obtenido al emplear ambos indicadores, nos permite apreciar la diferencia que existe entre ellos.

Aunque nos falto analizar todo el plugin, espero completarlo en otra oportunidad, pero también integrando herramientas similares, sobre todo para el caso de los análisis de clusters o agrupamientos.
Hasta otra oportunidad, líneas abajo les dejo las referencias que me permitieron preparar este post.
Referencias:
- Visualist: plugin for crime analysts
- Indicadores de asociación espacial
- Cómo funciona Análisis de cluster y de valor atípico (I Anselin local de Moran)
- Cómo funciona Análisis de puntos calientes (Gi* de Getis-Ord)
- Autocorrelación espacial e indicadores locales de asociación espacial. Importancia, estructura y aplicación.
4 comentarios:
Excelente entrada, muchas gracias por compartir sus conocimientos con la comunidad QGIS. Saludos.
Gracias por tu comentario José Antonio, voy a tratar de seguir compartiendo otros aplicaciones del QGIS
can i ask u one thing y population data is used in this plugin ,this plugin is mainly used for crime analysis
Ya no funciona en las nueva actualización de python, por la librería de scipy
Publicar un comentario